

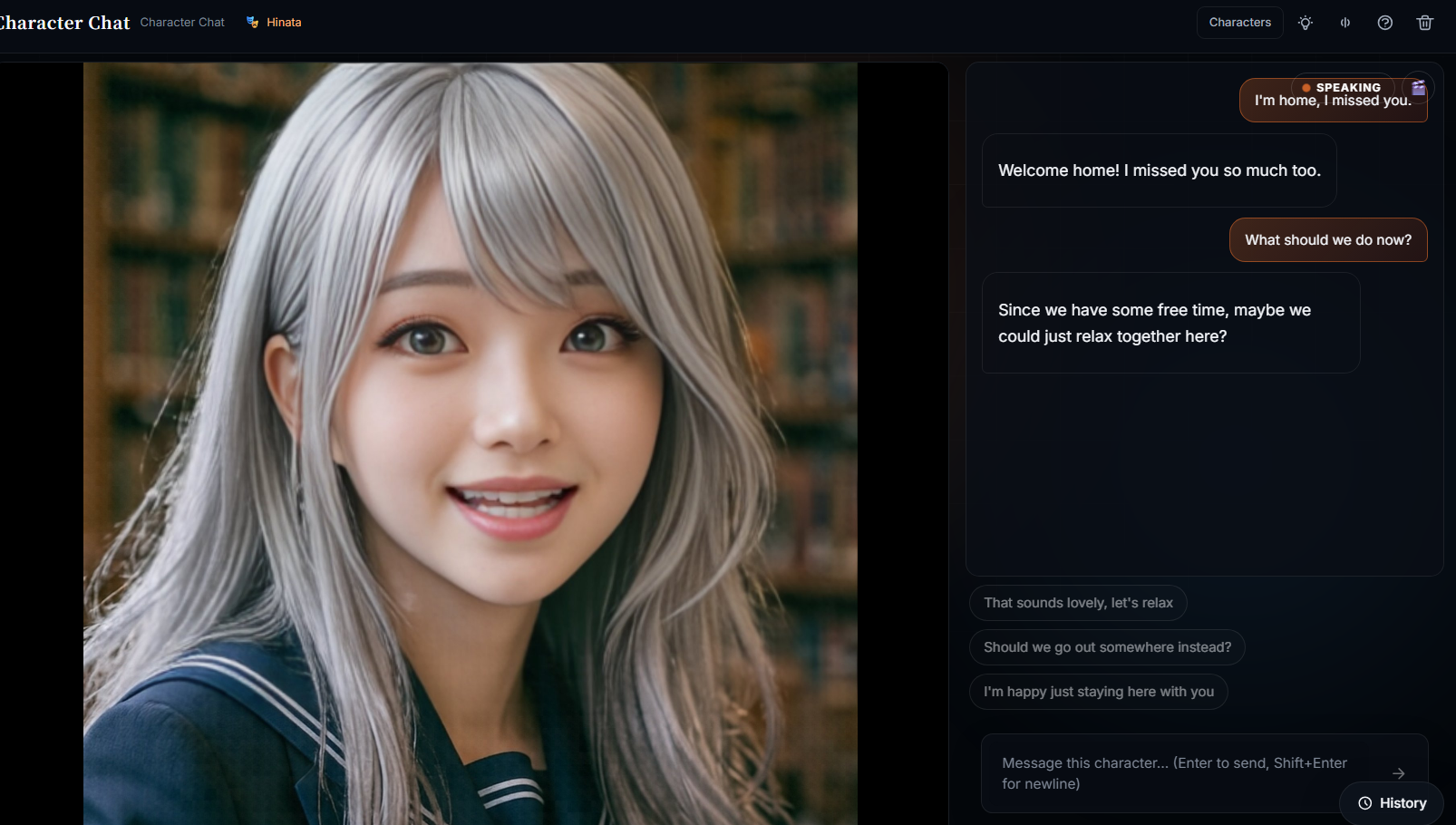
 この記事のアプリ
この記事のアプリKotonia
解決したかったこと
AIと「会話する」体験は一気に普及したけれど、その多くはテキスト中心。声で、キャラクターと、継続的に関係を築ける没入体験にはまだ穴がありました。特に、日本語・英語・中国語を高品質な音声+リップシンクのアバターで、低遅延(返答約1~2秒)で話せるものが見当たらない。語学の練習相手にもロールプレイの相棒にもなる「声で会えるAIキャラ」を作りたかったのが出発点です。
なぜ作ろうと思ったか
汎用AIチャットはモデル提供元(Anthropic / OpenAI / Google)とのコスト勝負になり、個人では勝てません。B2Bの音声AIもVCバックのダンピング営業で個人に不利。一方で「多言語 × 高品質リップシンク × 感情の継続」という没入UXは、大手のR&D優先度が低い残存領域でした。ここなら1人でも磨けば差別化が立つ。そう考えて、コア体験(音声会話 × アバター × 継続ペルソナ)に全振りしたサービスとして Kotonia を作りました。
こだわったところ
・低遅延の音声パイプライン(VAD → STT → LLM → ストリーミングTTS)で返答を高速化
・口の動きが同期するリップシンクアバター
・日本語 / 英語 / 中国語のマルチリンガル対応
・モデルはローカルGPU上のオープンモデルを活用し、品質と価格を両立
・キャラの記憶・人格が継続するので、使うほど関係性が育つ
裏側では、音声リアルタイム経路を専用GPUに物理隔離するなど、体感速度のための最適化にもかなり手を入れています。
最後に
技術的なお話はKotoniaサイト内の記事でも記載しております。→https://kotonia.ai/articles/
こちらにはデモ動画を載せております。低遅延の会話をご確認いただければと思います。→https://youtu.be/gubxZYryWq8
実際に使ってみる
Kotonia
この記事が良かったら
「チップをリクエスト」で著者にチップの受け取り設定をお願いできます